

Trên là một câu hỏi rất hay về việc xử lý lượng dữ liệu vô cùng lớn và có nhiều giải pháp được các bạn trong cộng đồng đưa ra. Chung bài toán gần như vậy, nay chúng ta cùng tìm hiểu bài toán tại Uber, và xem cách họ xử lý với lượng dữ liệu khổng lồ như nào nha!!
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Uber là một trong những công ty hàng đầu về ứng dụng đặt xe trực tuyến với hơn 150 triệu người dùng và gần 10 tỷ chuyến đi được hoàn thành trong năm 2023. Với quy mô lớn như vậy, dữ liệu liên tục được tạo ra từ mỗi chuyến đi, mỗi tài xế, và mỗi tương tác trên nền tảng là không hề nhỏ.
Uber xử lý hàng triệu chuyến đi mỗi ngày trên toàn cầu. Dữ liệu này bao gồm nhiều thông tin chi tiết về mỗi chuyến đi như thời gian bắt đầu và kết thúc, vị trí, tài xế liên quan, khách hàng liên quan, và nhiều yếu tố khác.
Một bài toán tưởng chừng đơn giản mà Uber cần làm đó là đếm số lượng các chuyến đi của từng tài xế trong các khoảng thời gian khác nhau (ngày, tuần, tháng) để đánh giá hiệu suất của tài xế, xác định số tiền mà tài xế cần được trả dựa trên số lượng chuyến đi hoàn thành.
Nhưng với lượng dữ liệu khổng lồ như trên thì đây là một bài toán khá khoai. Uber cần truy vấn và phân tích dữ liệu trong thời gian thực để đưa ra các quyết định nhanh chóng. Điều này bao gồm việc cập nhật số lượng chuyến đi một tài xế hoàn thành trong các khoảng thời gian khác nhau (ngày, tuần, tháng). Việc này đòi hỏi hệ thống phải có khả năng xử lý và truy xuất dữ liệu với độ trễ thấp. Hơn nữa dữ liệu của Uber còn được lưu trữ trên các máy chủ khác nhau. Điều này càng làm tăng độ phức tạp của bài toán.
Vậy Uber đã giải quyết bài toán này như nào nhỉ 🤔🤔
Câu trả lời đó chính là Apache Pinot, Uber đã giải quyết bài toán này bằng cách sử dụng Apache Pinot, một hệ thống phân tích dữ liệu thời gian thực. Apache Pinot giúp giảm độ trễ trong truy vấn và xử lý dữ liệu, cung cấp thông tin gần như ngay lập tức cho các quyết định kinh doanh. Điều này giúp Uber duy trì hiệu suất cao và đáp ứng nhu cầu phân tích dữ liệu của mình. Cùng Sydexa.com đi dạo một vòng tìm hiểu nha
1. Giới thiệu về Apache Pinot
Apache Pinot là một cơ sở dữ liệu phân tán mã nguồn mở được tạo ra tại LinkedIn vào giữa năm 2010. Nó đã được open-source vào năm 2015 và được tặng cho Apache Foundation vào năm 2019.
Với khả năng xử lý dữ liệu lớn theo thời gian thực, Pinot đã trở thành một giải pháp lý tưởng cho các doanh nghiệp cần phân tích dữ liệu một cách nhanh chóng và hiệu quả, và trở thành một trong những công cụ hàng đầu trong việc xử lý phân tích trực tuyến (OLAP).
Uber cần theo dõi số lượng công việc của tài xế – một bài toán OLAP điển hình đòi hỏi khả năng xử lý dữ liệu lớn. Pinot đáp ứng yêu cầu này nhờ ba tính năng nổi bật:
- Khả năng mở rộng: Pinot được thiết kế để mở rộng theo chiều ngang bằng cách chia nhỏ dữ liệu thành các phân vùng và phân phối chúng trên nhiều nút (node). Điều này cho phép Pinot xử lý lượng dữ liệu khổng lồ và đáp ứng nhu cầu truy vấn ngày càng tăng mà không gặp phải nút thắt cổ chai) bottle-neck về hiệu suất.
- Truy vấn nhanh: Pinot sử dụng định dạng lưu trữ dạng cột, điều này cho phép Pinot chỉ cần đọc các cột liên quan đến truy vấn, giảm thiểu lượng dữ liệu cần xử lý và tăng tốc độ truy vấn đáng kể.
- Làm mới dữ liệu: Pinot không chỉ xử lý dữ liệu theo batch mà còn có khả năng nhập dữ liệu từ các luồng dữ liệu thời gian thực như Kafka. Điều này đồng nghĩa với việc dữ liệu mới được cập nhật liên tục và sẵn sàng cho việc truy vấn chỉ trong vài giây.
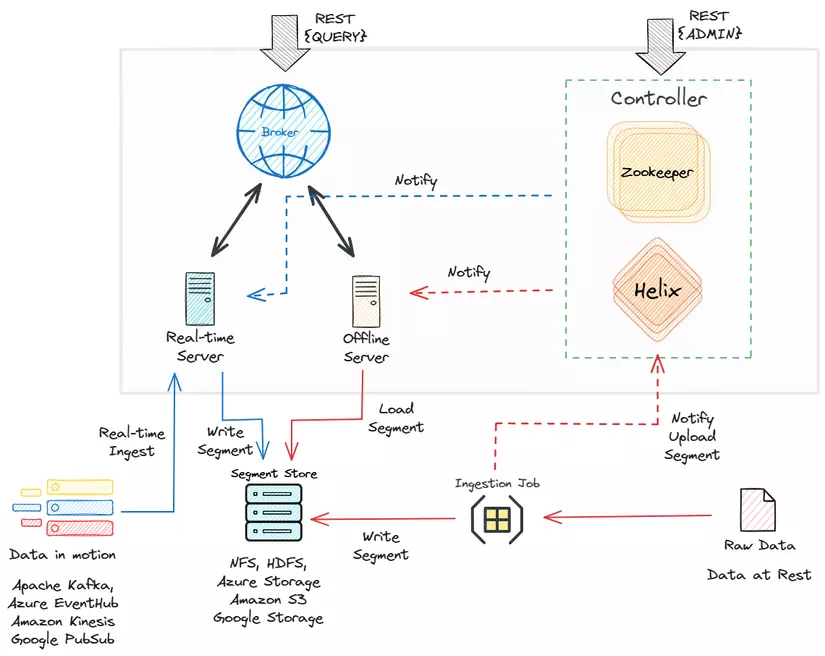
- Raw Data: Dữ liệu ban đầu, chưa qua xử lý được nhập vào hệ thống.
- Ingestion Job: Xử lý dữ liệu thô và chuyển đổi chúng thành định dạng phù hợp để lưu trữ trong Pinot.
- Segment Store: Nơi lưu trữ các đoạn dữ liệu đã qua xử lý. Các đoạn này là đơn vị lưu trữ cơ bản trong Pinot.
- Realtime Server: Xử lý việc nhập dữ liệu thời gian thực.
- Offline Server: Quản lý việc nhập dữ liệu theo từng batch.
- Broker: Hoạt động như một cầu nối giữa các máy chủ và các máy khách. Nó nhận truy vấn từ các máy khách và chuyển chúng đến các máy chủ thích hợp (thời gian thực hoặc ngoại tuyến) để truy xuất dữ liệu.
- Zookeeper (ZK): Điều phối và quản lý hệ thống phân tán. Nó giúp duy trì trạng thái cụm và quản lý cấu hình.
- Helix: Một khung quản lý cụm tự động, giúp quản lý tài nguyên phân vùng, sao chép và phân tán.
- Controller: Giám sát hoạt động tổng thể và điều phối cụm Pinot. Nó sử dụng Zookeeper và Helix để quản lý cụm và lưu trữ metadata.
Pinot lưu trữ dữ liệu trong các tệp phân đoạn, thường có kích thước từ 100-500 MB. Các tệp phân đoạn được lưu trữ trên các nút máy chủ Pinot và sao lưu trên AWS S3/HDFS/Google Cloud/v.v.
Dữ liệu thời gian thực có thể được nạp từ Kafka, EventHub, Google PubSub, v.v. và dữ liệu hàng loạt có thể được nạp bởi một máy chủ khác.
2. Những vấn đề mà Uber gặp phải
2.1 Ước tính dung lượng
Apache Pinot, công cụ cốt lõi trong hệ thống đếm số lượng công việc của Uber, sử dụng nhiều kỹ thuật nén dữ liệu khác nhau nhằm tối ưu hóa không gian lưu trữ. Tuy nhiên, điều này cũng gây ra khó khăn trong việc ước tính chính xác dung lượng lưu trữ cần thiết.
Các Kỹ Thuật Nén Dữ liệu trong Pinot:
- Dictionary Encoding: Thay thế các giá trị lặp lại (ví dụ: ID tài xế, thành phố) bằng các ID tương ứng trong một Dictionary, giúp giảm đáng kể kích thước dữ liệu.
- Fixed Bit Compression: Sử dụng số bit tối thiểu cần thiết để biểu diễn các số nguyên. Ví dụ, một số nhỏ như 5 có thể được biểu diễn bằng 3 bit thay vì 8 bit thông thường.
- Inverted Index: Không hẳn là một kỹ thuật nén dữ liệu, nhưng Inverted Index giúp tăng tốc độ truy vấn bằng cách tạo ra một chỉ mục ánh xạ các giá trị tới vị trí của chúng trong dữ liệu.
0 Nhận xét